
 Por volta de um mês atrás, escrevi um post acerca das virtudes do MySQL 5.6 RC (release candidate), dizendo que não havia problema algum e que tudo ficaria bem. Mas, agora percebo que disse isto cedo demais. Não se aflijam! Eu explicarei o motivo, e, a maioria dos usuários não foram afetados!
Por volta de um mês atrás, escrevi um post acerca das virtudes do MySQL 5.6 RC (release candidate), dizendo que não havia problema algum e que tudo ficaria bem. Mas, agora percebo que disse isto cedo demais. Não se aflijam! Eu explicarei o motivo, e, a maioria dos usuários não foram afetados!
Antes de mais nada, agora que o MySQL 5.6 já está em produção (GA – General Available), é uma ótima idéia que todos migrassem seus RDBMS para no mínimo a versão 5.6.10 GA. No entanto, cabe dizer que ainda não obtive evidências que o problema que será descrito à seguir tenha sido resolvido, dada à sua intermitência.
Pois bem, o MySQL 5.6 trouxe uma série de novidades, destacando-se aquelas relacionadas à replicação. A replicação do MySQL sempre foi uma característica nativa robusta e interessante. No MySQL 5.6 criou-se o conceito de “parallel coworkers” (colegas de trabalho paralelos).
Para entender o conceito de paralell coworkers, e, precisamos revisitar o funcionamento interno da replicação no MySQL.
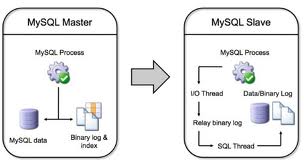
Toda a replicação no MySQL é serializada. O servidor Master (principal) recebe e processa vários comandos SQL de escrita, de uma única vez, de forma concorrente. Estes comandos são gravados, de forma organizada, um após o outro, em série. No servidor Master, ao “mesmo tempo” que os comandos SQL de escrita são aplicados, diretamente, na base dados, são também gravados, como descrito anteriormente, em uma arquivo chamado binary log, que é toda a base para a replicação no MySQL.
Já no SLAVE (servidor secundário, geralmente, usado somente para leitura) acontece algo mais interessante. Através de uma thread interna (sessão) chamada I/O Thread, o SLAVE faz um download do binary log, gerando, um novo arquivo (ou réplica) com o nome de relay log. Note que a única coisa que de fato ocorreu, foi a replicação do binary log, agora chamado de relay log. Ou seja, o comando SQL de escrita vindo do servidor MASTER está garantido, será aplicado, mas, ainda não foi!
Agora, uma nova thread (sessão) chamada SQL Thread encarrega-se de ler os dados do relay log e aplicá-los na base. Como os comandos estão serializados, um comando por vez será aplicado. Qual o problema nisso? Se quatro comandos, digamos UPDATE, são aplicados no servidor MASTER, em tabelas diferentes, cada qual levando 5 minutos para ser executado, no MASTER, os 4 serão executados em 5 minutos, pois, hipoteticamente, “chegaram” ao mesmo tempo, e, como o MASTER os processa, simultaneamente, temos que os 4 serão concluídos em 5 minutos.
Já no SLAVE, dada a arquitetura da replicação. Os quatro levarão 20 minutos para serem concluídos! Pois, será executado o primeiro, e, somente após sua conclusão será executado o segundo. E assim por diante.
Normalmente, isto não é um grande problema. Mas, dependendo do tipo de aplicação, chega a aborrecer.
Para evitar este problema (Ufa!) a Oracle pensou em criar múltiplos SQL Threads, que aplicam vários comandos de escrita, previamente gravados no relay log, ao mesmo tempo. Esta funcionalidade ganhou o nome de parallel coworkers. Legal e intuitivo o nome escolhido.
Quando fiz os primeiros testes fiquei muito animado com os ganhos. Mas, me deixei ser conduzido pelo manual. Existem algumas regras importantes para o uso do parallel coworker que deixarei para outro post.
Basicamente, para configurar o parallel coworker, basta, atribuir um valor à variável de configuração: slave_parallel_worker. Por exemplo, se voce quiser que hajam 4 SQL Threads rodando, simultaneamente, configure: slave_parallel_worker = 4.
Como já disse antes, existem alguma regras e restrições que devem ser observadas.
O problema surge quando voce tem configurado, em seu SLAVE, a variável replicate-ignore-db. Esta variável é responsável para dizer à SQL_THREAD: “Ei, não aplique nenhum comando de escrita referente a este banco, especificamente!”.
Sim… bem… ok… deveria ser assim. Mas, com uma intermitência irracional, os coworkers tem colidido entre si, e, tentado aplicar comandos de escritas que existem no servidor MASTER, mas, não existem no servidor SLAVE, por isso, o uso do replicate-ignore-db.
Portanto, gostaria de deixar esta dica registrada. Aparentemente, na versão 5.6.10 GA o problema foi resolvido, ou, pelo menos, amenizado.